
Object detection
Overview
What is object detection?

Object detection is a computer vision technique that aims to identify objects of interest in an image, such as vehicles, people, or buildings. During object detection, the model is applied to an input image, and the model outputs a set of bounding boxes and class labels, indicating the location and identity of the objects in the image. The model can also estimate the confidence score of each detection, indicating how confident it is in the detection being correct.
There are several reasons why object detection is used in computer vision:
-
Automation: Object detection can be used to automate tasks that would otherwise require manual intervention, such as monitoring surveillance cameras, detecting and counting objects in an image, or tracking moving objects in a video.
-
Object Tracking: The object detection model can be used to track objects in images. Typically, object detection models are combined with tracking algorithms to track objects.
-
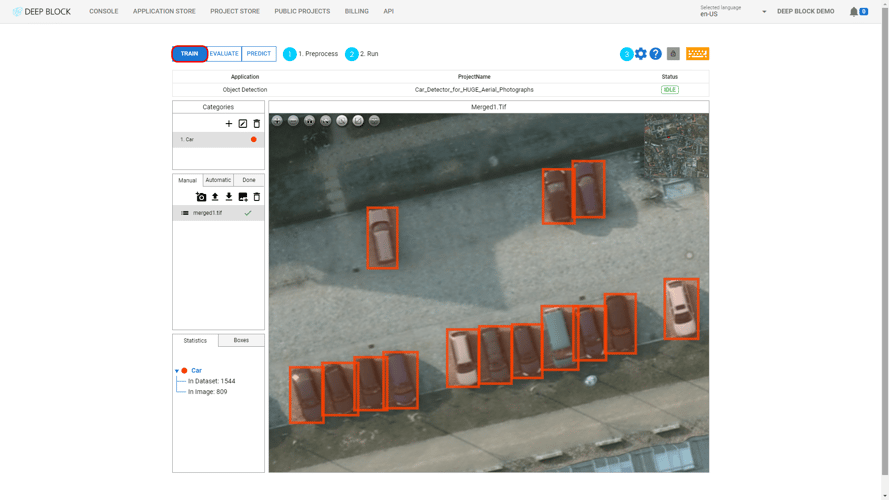
Object Counting: Counting objects is very important in the medical and pathology fields. The number of objects found through Object Detection can be easily checked through Deep Block.
-
Context Awareness: In order to understand videos or complex images, we need to understand where and what objects exist in these images and videos. For this purpose, the inference results of the object detection model must be passed back to the multi modal ML model as input.
-
Object Classification: Sometimes, people need to classify images or objects. Object detection is much more useful than a simple image classification model because it detects an object and at the same time tells you what category the object belongs to.
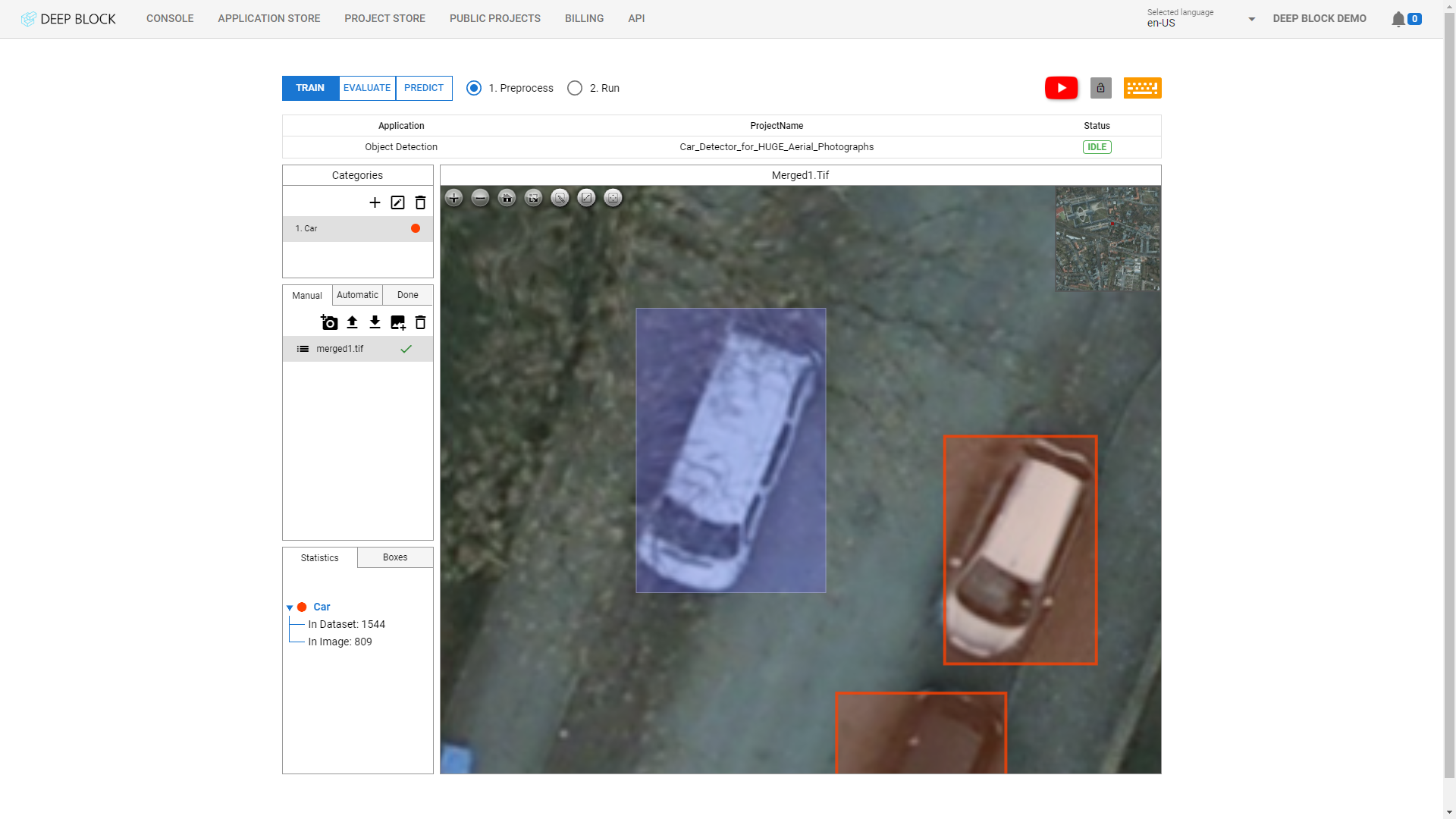
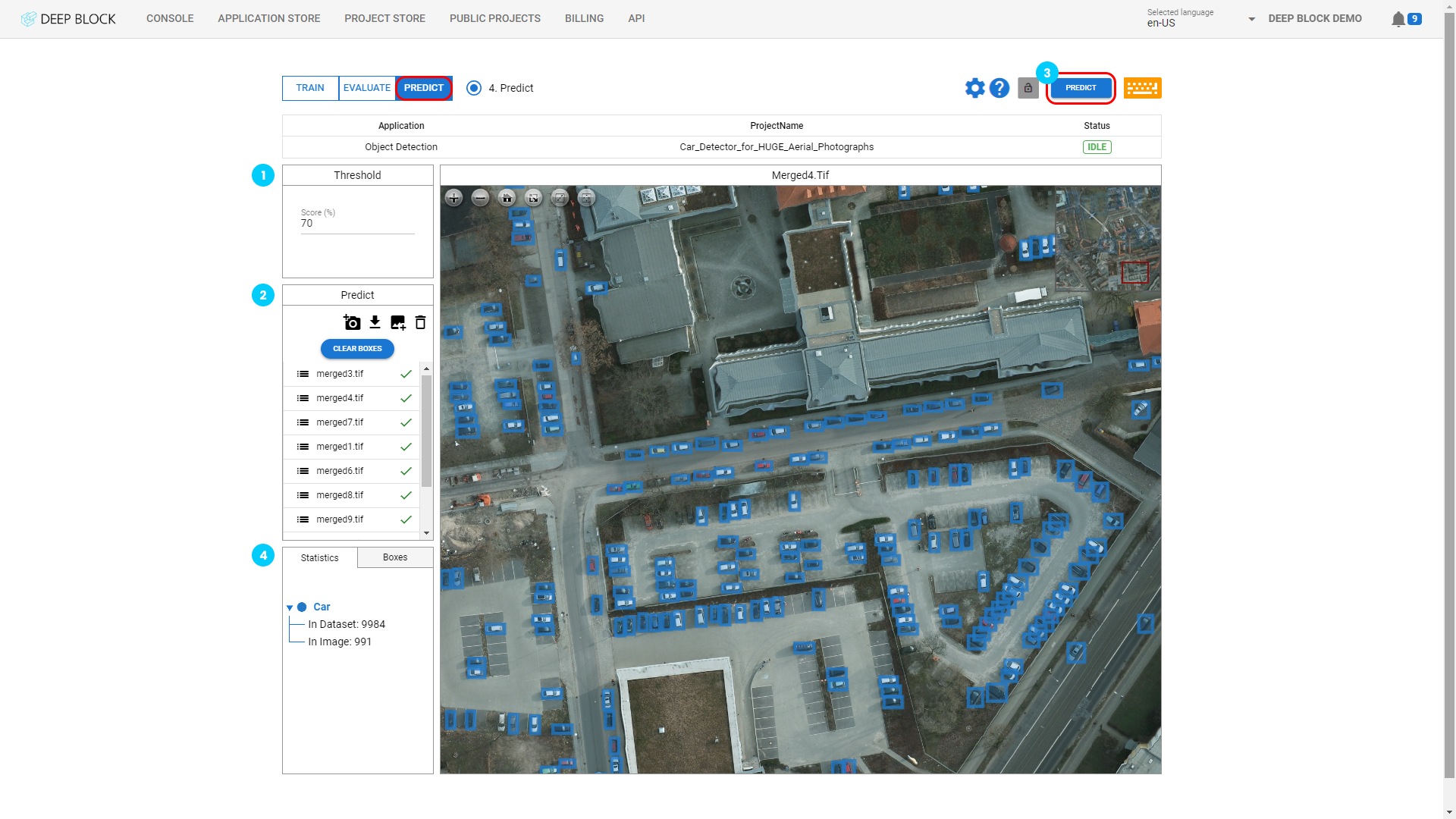
The threshold score refers to the detection sensitivity of the trained machine learning model.
If the threshold value is low, the machine learning model tries finding as many objects as possible with little confidence.
If the threshold score is high, the machine learning model only show analysis results that they can guarantee.
After training the model, we recommend that you first analyze the image with a low threshold value to check the confidence score of all found objects, and then gradually increase the threshold score to determine the optimal threshold score.
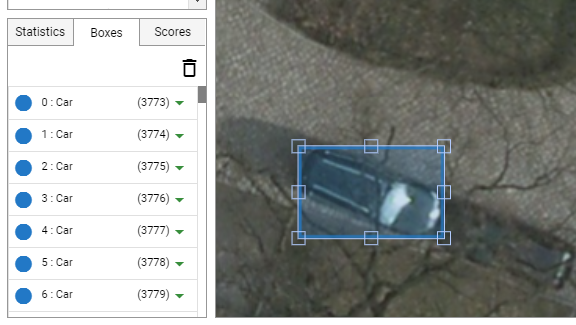
You can first analyze the image with a low threshold score, then check the confidence score of each bounding box resulting from the image's inference result, and increase the threshold value higher than the confidence score of the false positive case to improve the inference accuracy of the machine learning model.
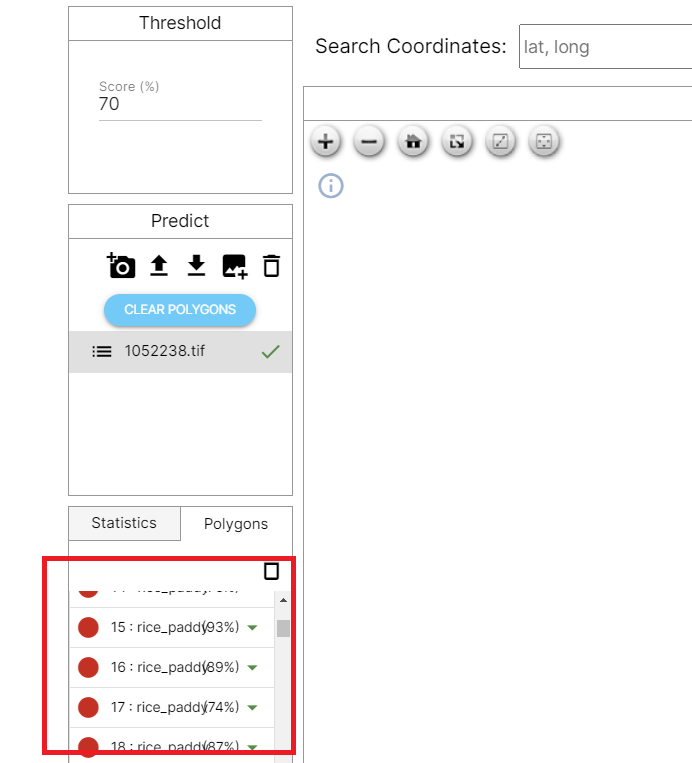
This allows you to set the optimal threshold value to find objects while reducing false positive cases.
- Enter the appropriate value in the Threshold score (%) field.
The choice of threshold value in object detection is an important step in the process, as it can significantly impact the quality of the detection results.
When inference is performed with a well-trained machine learning model, you can set a high threshold score, and all target objects present in the image are accurately captured.
Build the most accurate ML models with our team if you need a precise object detector.
- Click on "
 " to add an image via your webcam.
" to add an image via your webcam. - Click on "
 " to download the JSON file for the current project.
" to download the JSON file for the current project. - Click on "
 " to import images that you wish to use.
" to import images that you wish to use. - Click on "
 " to remove an image after selecting it.
" to remove an image after selecting it. - If a prediction has already been made, click on "CLEAR BOXES" to remove all bounding boxes.
Image file formats supported are: png, apng jpg, svg, tiff, bmp, gif, ico and jp2 (10GB max file size).
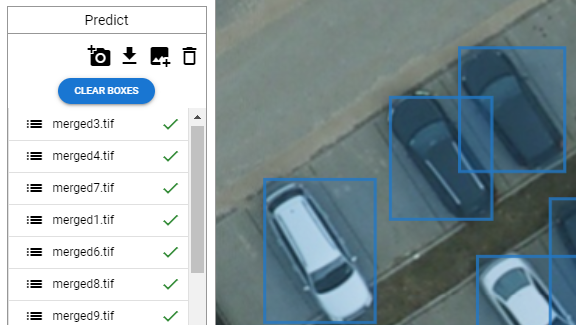
Once your dataset is uploaded, you are ready to launch the prediction.
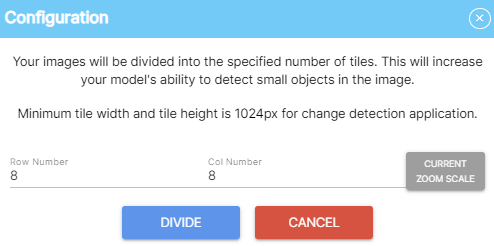
The important thing here is that when analyzing a large-scale image, the image must be divided into sections and analyzed.
Please refer to the following articles regarding this:
Segment Aerial Photos with an AI Model Trained on Drone Photos
The Power of Deep Block's Patented Algorithm for Large-Scale Image Analysis
- First, if the image resolution is large, divide it as you would when training the image.
We recommend using the More Accurate option to analyze images more accurately.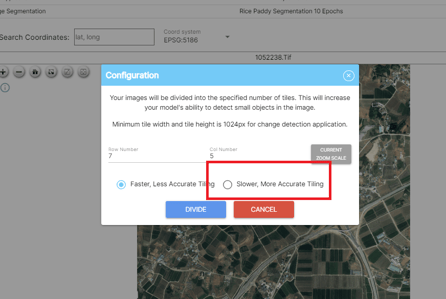
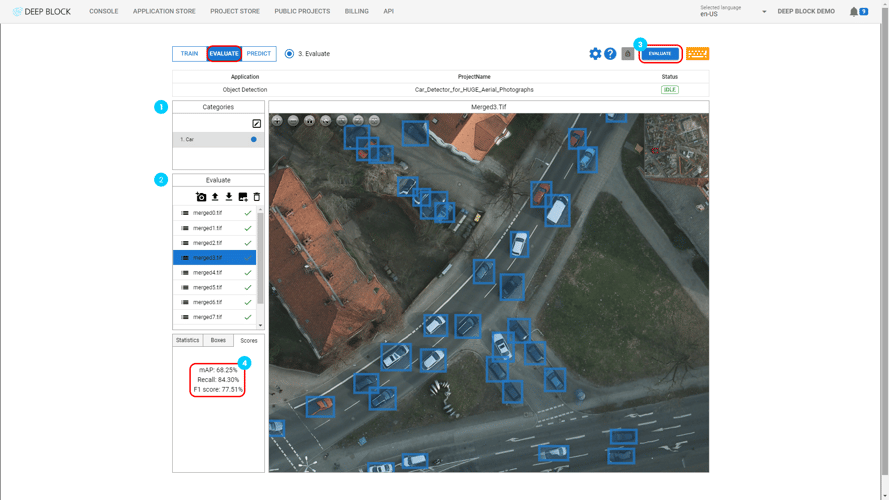
- Click on "PREDICT" at the top-right corner of the Project view.
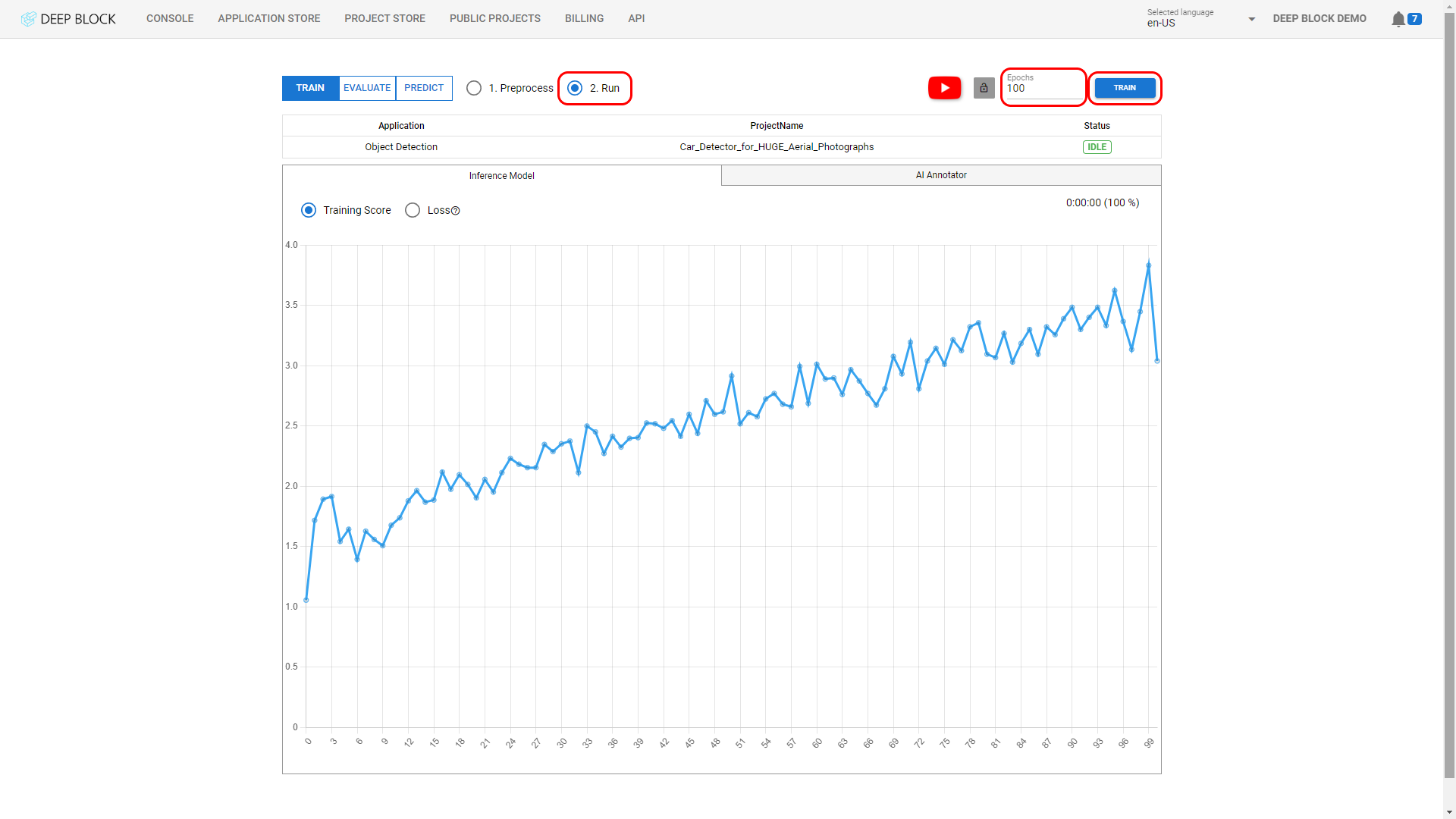
- The processing will start. Depending on the number of images uploaded, this process could take several minutes. You can stop it at any time by clicking on "STOP".
Wait until the processing status returns to "IDLE". By then, the model would have created bounding boxes around the desired objects of interest.